LHS智能医学系统实用指南
陈安均博士,LHS 技术论坛项目 联合主席,国际 LHS 社区(非营利),加州硅谷
[1/2/2023 更新。英文原文]
目录
- LHS 智能医学系统的愿景
- 医学证据和知识的生成
- 医学知识和模型的传播
- 构建 LHS 智能医学系统
- 机器学习赋能的 LHS 模拟研究
- 机器学习赋能的 LHS 项目实例
- 医疗健康数据
- 合成患者病历数据
- LHS 作为医疗人工智能框架
- LHS 相关资源
概述
《LHS 智能医学系统实用指南》专注于为软件开发人员和医疗健康机构临床团队提供技术实用信息,帮助您快速启动对未来 Learning Health System (LHS) 智能医学系统的研发和应用。
指南内容基于我对美国医学科学院 (US National Academy of Medicine, NAM) 发表的 LHS 系列报告的理解和解读,以及 LHS 这一新领域迄今为止取得的进展。NAM 提出的 LHS 愿景和制定的 LHS 顶层框架不仅将引导美国整个医疗健康系统向智能医学循环学习和传播系统转型,而且会影响全球各国医疗健康系统的更新。
本指南首先总结了 NAM LHS 系列报告,以期回答 LHS 基本问题:我们为什么需要 LHS?什么是 LHS?谁在搭建 LHS?
然后指南简要描述了应用机器学习 (machine learning, ML) 构建 LHS 小型单元的最新技术发展。亮点是首次使用合成患者数据模拟的机器学习赋能的 LHS (即 ML-LHS),所用数据可在 GitHub 上的 “开放合成患者数据” (Open Synthetic Patient Data) 项目获取。出于示范目的,指南分享了来自不同医院或医疗系统的 LHS 项目实例,这些项目正在为疾病风险预测和精准医疗等不同临床任务构建真实患者的 ML-LHS 单元。为加速 LHS 发展,我提出了一个“合成+真实”数据的新策略,有助于更有效地构建 ML-LHS 单元。
随后的章节提供了有关 ML-LHS 不可或缺的电子病历数据(electronic medical record, EMR 或 electronic health record, EHR)、合成患者数据、数据驱动的机器学习以及其他技术组件的更多详细信息。
指南主要目标:
- 为软件开发者和医疗健康机构临床团队提供实用技术信息,帮助快速了解 LHS 的优点并开始研发 LHS。
- 解释为什么构建小型 ML-LHS 单元更切实可行,而不应被另一种大而全的 LHS 构想所束缚。
- 提出“合成+真实”新策略:首先利用合成患者数据模拟 ML-LHS 单元,然后应用模拟流程帮助构建真实病历数据的 ML-LHS 单元。
指南还对 ML-LHS 提出以下假设:
- ML-LHS 性能假设:因其内在的以数据为核心的机器学习方法,ML-LHS 最终可以为大多数疾病和健康状况实现高性能的预测 (>95%) 。
- ML-LHS 平等假设:由大医院主导的临床研究网络 ML-LHS 可以有效地用机器学习模型为小型医疗机构赋能,从而减小在医疗服务不足人群中的医疗服务差异 (health care disparities)。
- ML-LHS AI 假设:因为 LHS 具有数据驱动和部署导向的特征,大部分基于电子病历数据的 AI 将以 LHS 形式更有效地实现和传播。
LHS 实用指南 是 GitHub 上开放 LHS 项目 (Open LHS) 的一部分,旨在智能医学系统新兴领域,促进全球范围的研究、开发和实施等方面的分享和协作。作为 LHS 的动态技术文档,本指南发布在 GitHub 平台,将在 LHS 新信息出现时进行更新,及时为 LHS 社区提供最新进展。
下一步:
在阅读本快速实用指南后,如果您想尝试病历机器学习或 ML-LHS 研究,可先在 GitHub 上的 开放合成数据项目 查看已有数据。如果您需要新的合成数据,可email我 (ajchen(at) web2express.org) 讨论如何产生新数据。合成数据有望加速您的项目进程,开源 Synthea 技术能够模拟各种疾病或健康状况,可能是您所需的合成数据的起点
【关于 LHS 名称翻译】
LHS 作为新的专业技术术语,本指南采用美国医学科学院发表的 LHS 系列报告中的定义。因为中文直译不能反映 LHS 的核心含义,我这里给出有助于理解的意译。
- 英文全称:Learning Health System。缩写: LHS。
- 中文全称:智能医学循环学习和传播系统。简称:LHS 智能医学系统。
1. LHS 智能医学系统的愿景
NAM 的 LHS 愿景
“In a learning health system, science, informatics, incentives, and culture are aligned for continuous improvement and innovation, with best practices seamlessly embedded in the delivery process and new knowledge captured as an integral by-product of the delivery experience.” (Source: NAM website - The Learning Health System Series)
LHS 愿景由美国医学科学院(前身为 US Institute of Medicine, IOM, 美国医学研究院)在一系列报告中提出和描述。下面我将总结报告中的相关信息,说明为什么需要 LHS,以及 LHS 是什么,并选出一些实例。如需详细信息,请参阅 NAM 网站上的 智能医学系统报告系列。
我们为什么需要 LHS?

2006 年,IOM 循证医学圆桌会议召开了一次题为“LHS 智能医疗系统”的研讨会,第一份 NAM 《LHS 智能医疗系统》报告于 2007 年发表。该报告指出美国医疗保健系统的表现仍然不尽人意。在剖析了临床证据的生成和应用过程之后,该报告设想了一个新的医疗健康服务系统,临床证据的产生及应用在医疗服务过程中持续不停地交互发生,即智能医疗保健系统。
在重新评估医疗服务如何产生及应用临床证据后,报告发现当前医疗系统存在以下问题:
- 问题:在医疗服务中经常错失良机,发生本可预防的疾病和受伤。
医疗失误问题:医学研究院 2001 年的报告《跨越医疗质量鸿沟》发现,每年约有 44,000 至 98,000 名美国人可能死于医疗失误。这个令人担忧的问题说明了重新设计医疗系统关键方面的需求,包括安全性、有效性、以患者为中心、及时性、效率和公平性。
- 问题:考虑到变化的速度和复杂性,目前流行的产生临床证据的方法是不充分的,并且可能很快就过时。
目前广受依赖的随机对照临床试验 (RCT) 虽然在一定情况下很有用,但太耗时、太昂贵,并且普遍适用性可质疑。
临床证据缺乏普遍适用性:临床研究通常不能可靠地产生能普遍适用于现实世界患者群体临床决策的证据。临床研究使用严格的患者纳入和排除标准,限制了大部分临床人群的参与。因此,即使完成了冗长的临床试验,临床医生仍然可能认为研究结果无法应用于自己的更加复杂的患者群体。例如,Masoudi 和同事发现,只有少数 (13-25%) 现实中的心力衰竭患者符合参加临床试验的入选条件 (Masoudi 2003) 。
- 问题:临床证据的数量、质量和应用方面都存在缺陷。
需要在全系统范围内更加注重临床证据,需要新的临床研究范式,可以更好地利用医疗服务过程中生成的数据,从而加快和改进能支持现实世界临床决策的证据研发。
- 问题:目前阐释证据的方法与制定指南和建议的方法常常会产生矛盾和混乱,指南的传播过于缓慢。
一份报告表明,一些好的研究结果需要长达 17 年时间才开始用于服务患者 (Balas, Boren 2000)。从创新到临床应用之间的滞后时间亟待缩短。
- 问题:低效和浪费在医疗服务中普遍存在。
在系统层面,临床研究与临床服务过程很明显是分离的。该 LHS 报告提出,将临床研究嵌入临床服务过程中可能会解决医疗系统中的这一基本缺陷。
简而言之,如果能够同时开展临床研究和临床服务,就可能提高持续学习和传播的效率和效果,从而大大提高医疗质量并同时降低费用。这就是为什么我们需要 LHS 智能医学系统。
什么是 LHS?
【资料来源:NAM 2007 报告《LHS 智能医疗系统》】
通过重新设计临床研究和医疗健康服务,《LHS 智能医疗系统》报告希望产生和应用最佳证据的过程可成为医疗服务过程本身的有机组成部分,这样就可以使智能医疗健康系统比当前更有效果、更有效率。
智能医学系统的特点:
- 文化:参与式、以团队为基础、透明、不断提升
- 设计和流程:以患者为中心并经过测试
- 患者和公众:全面积极地参与
- 决策:知情、促进、共享和协调
- 医疗服务:每次都从最佳实践开始
- 结果和费用:透明且不断评估
- 知识:临床服务和研究的持续和自然的结果
- 数字技术:持续改进的引擎
- 健康信息:可靠、安全和可重复使用的资源
- 数据应用:为了共同利益而管理和使用数据
- 信任结构:强大、受保护并积极培养
- 领导力:多焦点、网络化和动态性
美国卫生部医疗信息改革协调办公室 (ONC) 设想了一个全国性的智能医学系统 (Friedman 2010)。
重新定义 LHS
【资料来源:NAM 2013 年报告《低成本的最佳医疗服务》】
IOM 2013 年报告《低成本的最佳医疗服务:美国通往持续学习的医疗服务系统的途径》重申了 LHS 的愿景。 该报告探索了变革的必要性、使转型成为可能的所需新兴工具、可持续学习的医疗服务系统的愿景、以及实现这一愿景的途径。

该报告重新定义了将当前“破碎的”医疗系统转变为智能医学系统的需求:
- 需要一种新的途径来生成和应用医学知识。
目前产生新医学知识的方法存在不足,难以提供支持优质医疗服务所需的证据。临床证据不足,并且产生医学知识的方法有明显的局限性。
可能的证据与实际产生的证据之间的差距继续扩大。研究表明,指南中有证据支持的陈述的数量没有达到应有的水平。在某些情况下,40-50% 的指南推荐是基于专家意见、案例研究或医疗服务标准,而不是基于多项临床试验或元数据分析。
目前的研究知识库只能为回答重要类型临床问题提供有限的支持,包括效果比较和长期患者结果相关的问题。
临床指南证据不足会影响医疗服务的证据。在美国,基于临床研究获得的正式证据所做出的临床决策的占比,不同研究有不同的估算,有些研究发现仅占 10-20%。
- 知识需要快速传播。
心脏病发作后 β 受体阻滞剂的广泛使用在各方面来说都是一个成功案例:高质量临床证据生成;治疗方案被纳入临床指南、质量改进计划和医疗质量评价;还有些健康保险计划为提高该治疗方案的采用提供了经济激励。然而,即使做出这么大努力,从该治疗方案最初结果的发表到在临床实践中获得普遍应用,也经历了 25 年的时间。这个例子说明,有必要建设新基础设施,使临床学习和方案改进的过程更容易,争取下一个发现不再需要 25 年的持续努力才能广泛用于服务患者。
- 需要控制不可持续的高医疗成本。
为了提高质量、控制成本,需从目前不可持续且有缺陷的医疗系统组织架构,转变为一个可在每个医疗服务环节获取知识并促进持续改善的系统。简而言之,国家需要一个可不断学习的医疗服务系统,这个系统现在既是可能的,也是必要的。
智能医疗服务系统的定义:
“智能医疗服务系统是一种将试验科学、信息学、激励措施和文化有效结合,以达到持续改进和创新的系统,它将最佳临床实践嵌入医疗服务流程中,由患者和家庭在各方面积极参与,并且在临床服务中产生新知识。”(资料来源:NAM 2013 年报告《低成本的最佳医疗服务》)
智能医学系统示意图:
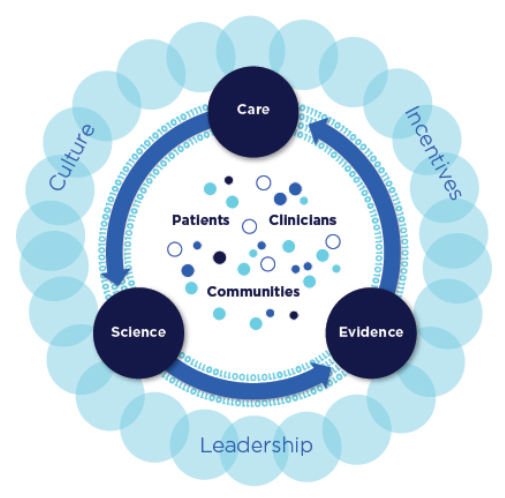
(资料来源:NAM 2013 年报告《低成本的最佳医疗服务》)
不断学习的医疗服务系统的特征
【资料来源:NAM 2013 年报告《低成本的最佳医疗服务》】
实验科学与信息学:
- 实时获取知识 —— 智能医疗系统能持续可靠地采集、解释和提供最佳证据,以指导、支持、定制和改进临床决策以及医疗服务安全和质量。
- 医疗服务体验的数据采集 —— 智能医疗系统在数字平台上采集患者对医疗服务的体验,实时生成和应用知识改善医疗服务。
患者-医生合作:
- 积极参与和赋权的患者 —— 智能医疗系统立足于患者的需求和观点,鼓励患者、家属和其他护理人员成为持续学习的医疗团队的重要成员。
激励措施:
- 与价值相一致的激励措施 —— 智能医疗系统积极地把激励措施与鼓励持续改进、发现并减少浪费、以及奖励高价值医疗服务相结合。
- 完全透明 —— 智能医疗系统能够系统地监控医疗服务的安全性、质量、流程、价格、成本和结果,并为服务改善及医生、患者和家属做出明智选择和临床决策提供信息。
持续学习的文化:
- 充满领导力的学习文化 —— 智能医疗系统由致力于团队合作、协作和适应文化的领导层领导,支持以持续学习为核心目标。
- 支持系统的能力 —— 智能医疗系统通过持续的团队培训和技能建设、系统分析和信息开发、以及为持续学习和系统改进形成反馈回路,不断完善复杂的医疗服务和流程。
谁在建造 LHS?
LHS实例:
- Intermountain Healthcare:建立反馈循环,加快研究的及时性和相关性。
- Geisinger Health System:使用电子病历弥合推理差距 (Inference Gap) 。
- 美国退伍军人医院:实施循证医疗服务,特别是通过使用电子病历。
临床研究网络LHS实例:
- 凯撒 (Kaiser) 医疗集团
- 美国国立癌症研究院 (NCI) 癌症研究网络
- 以患者为中心的智能医学系统网络 (LHSNet)
适合软件开发者的 LHS 定义
为了让开发者更容易理解 LHS,本指南提供一个更为简洁的技术性定义:
- 智能医学系统将研究嵌入医疗服务中,可同时收集医疗健康数据,不断地机器学习新知识和预测模型,并迅速把新改善应用于医疗服务中。
智能医学系统中的“学习”,是指在人正常学习之外的机器学习、持续学习,最终是系统自我学习。当临床研究和医疗实践无缝有机结合时,传统的知识传播大问题就开始自然地减轻。
从本质上讲,LHS 是关于医学知识产生和使用的基础性变革。接下来的两个章节将深入探讨这类“知识业务”。
2. 医学证据和知识的生成
研究方法
【资料来源:NAM 2013 年报告《低成本的最佳医疗服务》】
随机临床试验 (RCT) 是当前临床研究生成医学证据和知识的“金标准”。尽管科学发现的步伐在加快,但临床研究目前并不能充分解决紧迫的临床问题,结果是患者和临床医生都在证据不足的情况下做决定。
即使以目前的知识产生速度,知识库也仅仅能为回答许多最重要临床问题提供有限的支持。一项针对九种最常见慢性病临床指南的研究发现,只有不到一半的指南为患有多种合并症的患者提供治疗指南。
当前大型临床研究方法的成本平均为 1,500-2,000 万美元,有些甚至更高,但这些研究还不能反映许多医疗服务机构的实际情况。
需要新的方法来解决当前临床研究的局限性。替代研究方法包括:
- 适应性的临床试验
- 延迟设计的临床试验
- 整群随机对照试验
- 观察性的临床试验
- 病例对照研究
- 实用临床试验 (PCT)
- 大型简单临床试验 (LST)
替代方法还需要不同的统计分析:例如
- 新贝叶斯数据分析技术可以分离出不同临床干预措施对人群健康的影响。
- 生理路径和疾病状态的模拟。
- 机器学习。
实验性研究与观察性研究
实验性研究方法:
- 可以采用随机化,可以避免某些偏差,但既费时又费钱。
- 随机对照试验在产生新的临床知识方面有着非常成功的记录,但它有几个局限性:并非在所有情况下都实用或可行;昂贵且费时;仅解决设计要回答的问题;无法回答所有类型的研究问题。
观察性研究方法:
- 只能在群体层面随机化,更容易在医疗服务过程中收集数据,结果更接近真实世界的情况,需要的时间和成本更少。
- 观察性研究的优势在于能捕捉到真实世界情况下的医疗实践,有助于将其结果普遍推广到更多的医疗实践中。这种研究设计可以提供整个产品生命周期的数据,并可通过改变医疗服务的参数自然地开展实验。然而,观察性研究的挑战是如何减少数据偏差,以及如何确保其结果确实是试验选择的干预措施所致。
适用于 LHS 的观察性研究方法
NAM 2013 年研讨会总结报告《智能医学系统中的观察性研究》 (OS-LHS) ,回顾了观察性研究的主要方法、如何处理偏差、如何评估治疗异质性,以及在LHS中使用观察性研究方法的其他重要方面。观察性研究可以提供在真实世界临床实践中治疗方法有效性的信息。观察性研究方法是随机临床试验方法的补充,具有以下特点:
- 在普通人群中检测各种治疗方法的益处和风险。
- 发现由随机临床试验无法观察到的罕见副作用和益处。
- 提供社区范围数据,提出新假设,然后在临床试验中检验。
- 为研发预测模型提供数据。
- 估算个性化治疗的效果。
- 与随机临床试验结合应用,可检验临床试验结果在更具代表性人群中的有效性,并评估治疗异质性。
观察性研究方法的问题:
- 潜在偏差。
- 数据质量问题。
- 数据分析的挑战。
- 更难做出因果关系的结论。
关于观察性研究的偏差:
- 缺失信息或对健康结果相关的信息进行错误分类可能会导致偏差。
- 工具变量法是控制未测量的混杂因素的一种方法,可用于减少非随机试验存在的偏差。
- 由于潜在的偏差,观察性研究需要仔细设计,以防止误导性结果。从下面这个反面例子可以吸取教训:大量的激素替代疗法的观察性研究结果与妇女健康计划 (Women’s Health Initiative) 做的随机临床试验结果之间互相矛盾。
适用于LHS 的大型简单试验研究方法 (LST)
NAM 2013 年的研讨会总结报告《智能医学系统中的大型简单试验和知识生成》 (LST-LHS) ,描述了在 LHS 背景下的 LST 研究方法,并提供了成功的例子。 与随机临床试验相比,大型简单试验能回答有关药物和其他干预措施有效性的一些问题,成本更低、时间更短、或两者兼具。 该报告描述了进行大型简单试验所需的基础设施。使用电子病历是收集和管理大量患者数据必需的,电子病历可让临床试验在临床服务过程中开展。
从许多医疗机构招募足够数量的患者可能需要临床研究网络 (CRN) 或机构联盟。这些网络正朝智能医疗系统模式发展。在 CRN 中,临床医生和研究人员可以从更大的患者群体中学习,检查结果各异的诊断和治疗,找出可产生更好结果的因素。CRN 可以开展更大人群的临床试验,这对研究罕见病或不常见疾病尤为重要。
现在已有数据标准,如 FDA 项目发展出来的临床数据采集协调标准 (CDASH),也有可从多元化的电子病历系统采集数据的电子工具。
详情请见报告中以下专家的介绍:
- 哈佛医学院 Richard Platt 博士
- 美国退伍军人医院 Ryan E. Ferguson 博士
- 临床数据交换标准联盟 Rebecca Daniels Kush 博士
- 辛辛那提儿童医院 Carole M. Lannon 博士
挑战与新机遇
2016 年,NAM 组织了“加速临床知识的生成和使用”会议,并发表了一篇讨论报告《从最佳医疗服务中生成知识:推进持续的智能医学系统》 (Abraham 2016)。根据报告,尽管嵌入式学习活动大有前景,但临床运作和研究合作的障碍依然存在。
NAM LHS 系列报告发布后,EMR 已迅速在医疗机构中普及开来。同时,随着最近几年计算能力和算法研发的快速发展,NAM LHS 报告中尚未充分讨论的机器学习和人工智能 (AI) 技术出人意料地成为任何临床研究人员皆可运用的常见研究工具。
在我看来,这种前所未有的数字健康数据加之机器学习的环境正在为 LHS 背景下的医学知识生成带来不可估量的可能性。一方面,大量机器学习研究直接使用常规 EMR 数据,已学习和构建了有关诊断和治疗等临床事件的知识库。另一方面,从电子病历数据建造机器学习模型,既不需要先验知识,也不产生传统形式的知识。 机器学习模型,尤其是那些无法解释的模型,将把 LHS 中学习和传播新知识的传统概念推向一个未知领域——在不了解模型的知识来源和知识产物情况下传播机器学习模型。(在这种情况下,我们只知道模型有效,但不知为什么。)
3. 医学知识和模型的传播
通过基于知识的临床决策支持系统传播
【资料来源:NAM 2013 年报告《低成本的最佳医疗服务》】
当前产生和应用新临床知识的系统在很大程度上是相互脱节的,且协调不佳。虽然每年临床数据帮助开发了许多有效的循证临床实践、治疗方法和干预措施,但其中只有一部分被广泛使用。其他许多临床实际仅是在有限范围内使用,未能发挥其改善医疗服务的革新式潜力。
有证据表明,仅仅提供信息尽管速度更快,但很少能改变临床实践。因此,挑战在于如何能够以让临床医生采纳的方式传播知识。
将研究结果用于临床服务的一种技术工具是临床决策支持系统。临床决策支持系统将患者信息与包含临床研究结果和临床指南的数据库集成在一起。该系统生成个性化患者建议,指导临床医生和患者做临床决策。
随着知识生成速度的加快,需要新的方法将正确的信息以清晰易懂的格式传达给患者和临床医生,帮助他们共同做临床决策。报告的相关发现有:
- 医疗服务的新知识的传播和应用速度缓慢,会对患者造成伤害。例如,从首次获得临床试验正面结果到大多数专家开始推荐溶栓药物用于心脏病发作的治疗时,花了 13 年时间。
- 可用的临床证据通常未用于临床决策。一项对植入式心律转复除颤器 (ICD) 植入物使用情况的分析发现,22% 的使用是在专业协会指南之外的情况下植入的。
- 可在电子病历系统中广泛提供的决策支持工具有望改进临床证据的应用。一项研究发现,数字决策支持工具帮助了临床医生应用临床指南,将糖尿病患者的健康结果提升了 15%。
通过预测模型传播
电子病历数据尽管不完美,但可以产出相当准确的统计预测模型,这些模型通常比目前用于预测风险的、基于简单分期策略的模型更好(NAM 2013 OS-LHS 报告)。
正如之前的知识生成部分所述,机器学习模型可以从整个 EMR 或多个 EMR 构建。根据所使用的算法,有些模型是可解释的,有些则不可解释。无法解释的 ML 模型即使是高性能的,它们的传播也将面临挑战。
4. 构建 LHS 智能医学系统
NAM 报告的方法
NAM 2011 年的报告《智能医学系统的数字基础设施:持续改善健康和医疗系统的基础》探讨了利用现有技术及选择创新重点的已有努力和机遇,以确保在一个系统中收集的数据可以跨系统用于各种不同的用途。然而,LHS 基础设施的完整连贯图景仍不明朗。
NAM 2011 年研讨会总结报告《工程设计智能医疗服务系统的未来展望》,回顾了持续反馈和改进医疗服务的质量、安全性、知识和价值的工程方法。智能医疗系统的目标是每次都提供最好的诊疗,并在每次医疗服务中学习和改进。目前,美国在组织、管理和提供医疗服务方面都没能做到令人满意的可靠性、一贯性和可承受性。该报告盘点了可能适用于健康领域的工程学经验教训。然而,它没有提供构建实际 LHS 的指导。
NAM 2013 年的《低成本的最佳医疗服务》报告展示了一个复杂的 LHS,并得出结论:“鉴于系统的复杂性和各个部分的相互关联性,任何一个部分都无法单独达到开发一个不断学习和改进的医疗系统所必需的变革范围和规模。”(第 10 章 281 页)
本指南自下而上的方法
如果仅将 LHS 定义为最终的全国范围的智能医学系统,NAM 报告的上述结论可能是正确的。但这可能不是一个有效的方法 —— LHS 是如此复杂,以至于无人能够开始构建它。
我认为,为了系统实施的可行性目的,我们应该分不同阶段、在不同层面上定义和建造智能医学系统。最重要的是,LHS 的起点应该是现在就可以由一家医院、一个科室或一个小组建立的那种 LHS,无需依赖任何没必要的外部因素。
因此,本 LHS 快速指南采用自下而上的实用方法:将大型复杂的 LHS 分解为小型 LHS 单元;先设计和构建 LHS 单元,用于执行解决问题的具体任务;然后将功能性 LHS 单元连接成子系统。当多个子系统顺利运行后,再将子系统集成更大的智能医学系统。
由于我们仍处于构建智能医学系统的初期阶段,我们应该首先专注于构建足够数量的小型 LHS 单元作为示范。 在现阶段,LHS 领域最容易出成果的是什么?可能是基于 EMR 数据的预测型 LHS。例如,用于提高疾病早期诊断的智能风险预测系统,或个性化用药智能预测系统,都对医院有很强的商业价值,最有可能立项。
焦点:构建机器学习赋能的小型 LHS 单元
本指南侧重于为构建 ML 赋能的小型 LHS 单元 (ML-LHS) 提供实用指导和实例。通过应用机器学习模型,预测型或其他功能性的 ML-LHS 单元有望为医疗服务或公共卫生服务的许多具体任务提高效果和效率。
ML-LHS 单元的主要特性:
- 数据驱动。
- 机器学习。
- 持续学习。
- 快速传播。
- 自动流程。
现在,相关的开放数据和开源软件使得研发小型但有效的 ML-LHS 变得更加容易,这些技术在 NAM 编写 LHS 报告时还不存在,包括大量可供选择的免费和开源的机器学习算法和工具。在患者数据得到保护的情况下,有些共享的脱敏 EHR 患者数据在数据源网站上申请授权后可获得。对于任何疾病和健康状况,也可以通过 Synthea 等最新技术产生合成的患者病历数据,以补充真实 EHR 数据的缺失。合成数据可方便地用于研发 ML 算法和 LHS 流程、测试或培训。
以下章节将先描述应用合成患者病历首次模拟风险预测 LHS,随后是正在进行中的使用真实 EHR 数据的 ML-LHS 项目实例。基于这些研究的初步结果,我提出一个新的“合成+真实”策略,可更有效地用来构建小型 ML-LHS 单元:首先使用合成病历数据模拟 ML-LHS,然后将其流程应用于真实病历数据。
5. 机器学习赋能的 LHS 模拟研究
通过合成患者病历的新技术,现在已经能够合成病历模拟 EMR,然后用此虚拟数据模拟机器学习赋能的 LHS,探索 ML-LHS 的作用。LHS 模拟是一种研究 ML 算法和 LHS 流程的有效方法,研究结果可用于帮助使用真实患者数据构建 ML-LHS 单元。由于基于公共数据而合成的患者数据不存在隐私问题,LHS 模拟研究可跨机构大规模共享数据和协作研发算法和流程。这个模拟步骤有可能为整体 LHS 项目进度节约大量时间。
我们使用 Synthea 技术合成患者病历,进行了首次 ML-LHS 模拟研究,研究结果发表在《自然科学报告》杂志 (Nature Science Reports) (Chen 2022)。下面是该研究总结。
ML-LHS 核心单元的基本设计
用于风险预测任务的 ML-LHS 核心单元的简化设计如下图所示。该设计着重于模拟两个机器学习核心步骤:(1)从现有的 EHR 数据构建初始 ML 模型,(2)持续机器学习新增数据以改进 ML 模型。这种 LHS 设计利用了 LHS 内在的数据为驱动的 ML 方法。因此,ML-LHS 流程主要侧重于提高 ML 可用数据的质量和数量,以达到改进风险预测 ML 模型的目的。
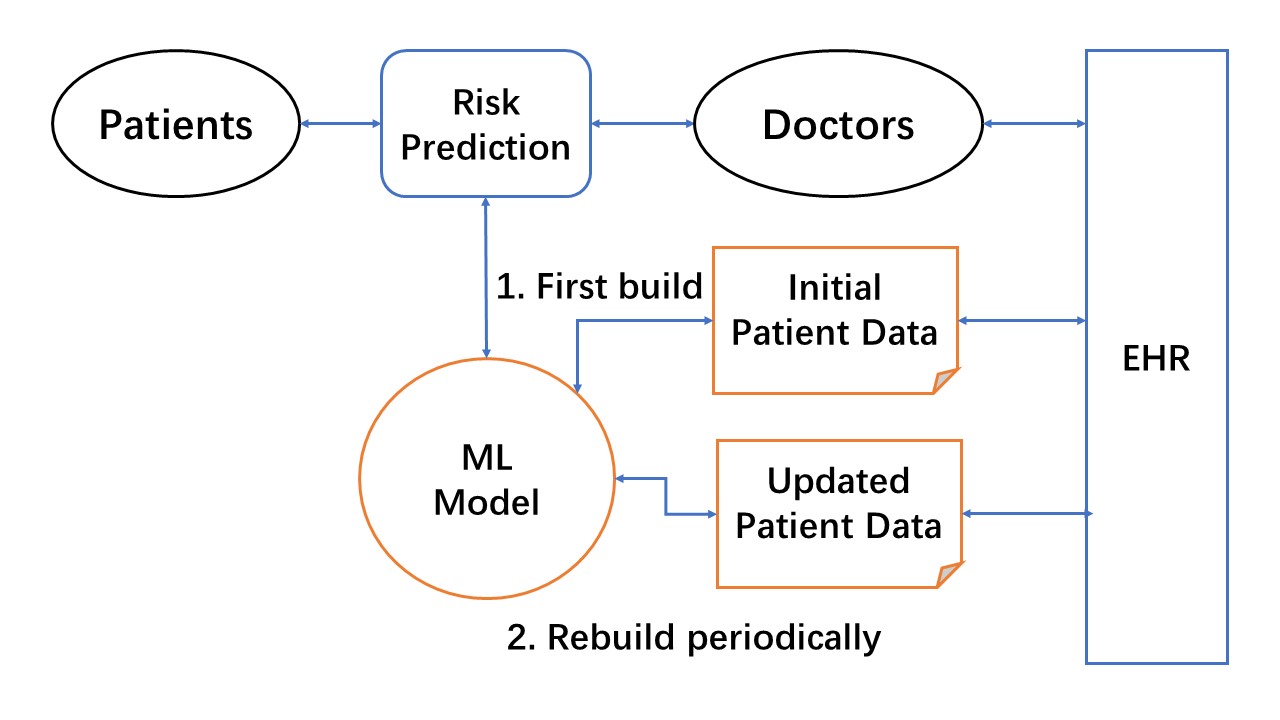
图示:风险预测 ML-LHS 核心单元的设计示意图。1. 先由现有病历数据构建 ML 模型。2. LHS 学习循环持续使用更新的患者数据改进 ML 模型,并将新模型快速应用到风险预测服务中。
肺癌风险预测模拟 ML-LHS 单元
为了模拟一个有 100 万患者规模的真实医院 EHR 的肺癌风险预测 LHS,模拟 LHS 需包含大约 5,000 名肺癌患者。Synthea患者合成软件 共合成了约 150,000 名患者的病历,其中约有 5,500 名患有肺癌。这些 Synthea 患者的 1,300 多万次就诊中有超过 1.75 亿数据点,包括 800 万个诊断、1.11 亿个观察、2,400 万个手术和 1,500 万个药物治疗。
模拟 ML-LHS 的持续学习和改进过程从 30,000 名 Synthea 患者开始,共模拟四次学习循环,每次增添 30,000 名 Synthea 患者。每次更新数据集后,重建新的 XGBoost 预测模型。随着数据集规模从 30,000 名患者增加到 150,000 名患者,肺癌风险预测模型效果逐步提高:肺癌召回率 (recall) 从 0.849 增加到 0.936,精确率 (precision) 从 0.944 增加到 0.962, AUC 从 0.913 增加到 0.963,准确度 (accuracy) 从 0.938 增加到 0.975。如下图,与随机森林算法 (RF)、支持向量机算法 (SVM) 和 K 最邻近算法 (KNN) 的基础模型相比较,Synthea 患者的 XGBoost 肺癌模型的风险预测能力最好。
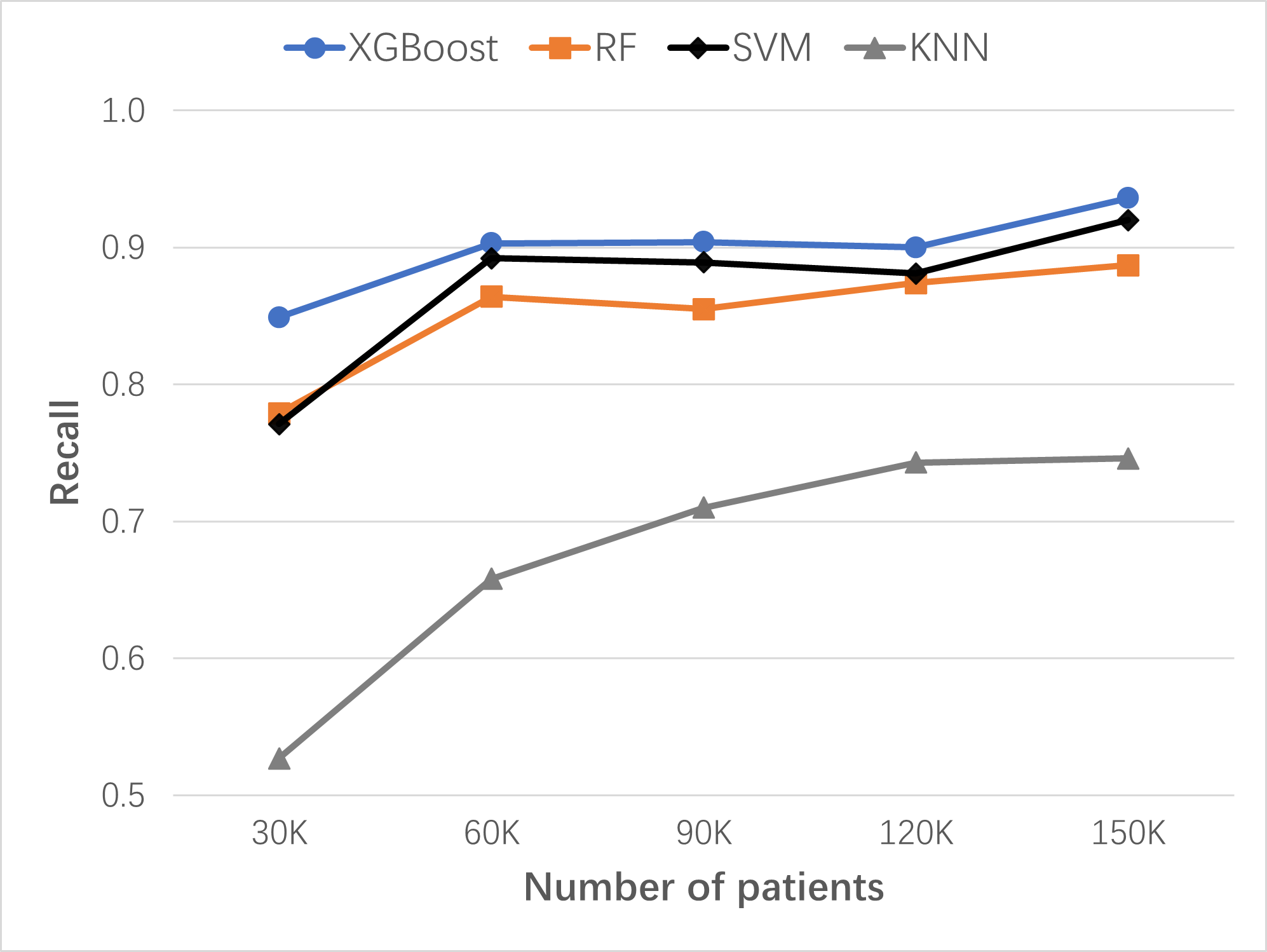
图示:随着数据量增加,肺癌风险预测 ML 模型在不断改进。比较四种算法的召回率 (recall): XGBoost、RF、SVM 和 KNN。初始数据集:30,000 名患者;有四次数据更新,每次增加 30,000 名患者。
以脑梗模型验证 LHS 流程
为了验证模拟研究建立的新型数据驱动的 ML-LHS 流程的可复制性,它应该可以为任何目标疾病(如脑梗)建立高效风险预测ML模型:在相同数量的数据更新迭代后,可达到高召回率和精确率。
Synthea 合成患者的脑梗发生率高于肺癌。每 30,000 患者中约有 4,000 名脑梗患者。与肺癌模型相似,脑梗模型的性能指标也随着每次数据更新而提高。在第四次学习和改进周期中,更新的 150,000 名患者中有 20,000 名脑梗患者,XGBoost 基础模型的关键指标提高到:召回率 0.908、精确率 0.964、AUC 0.948、准确度 0.969 (见下图)。
脑梗模型的结果证实,建立的LHS过程在构建脑梗风险预测的高性能模型方面同样有效。我们预计这种 LHS 过程也将适用于其他疾病。
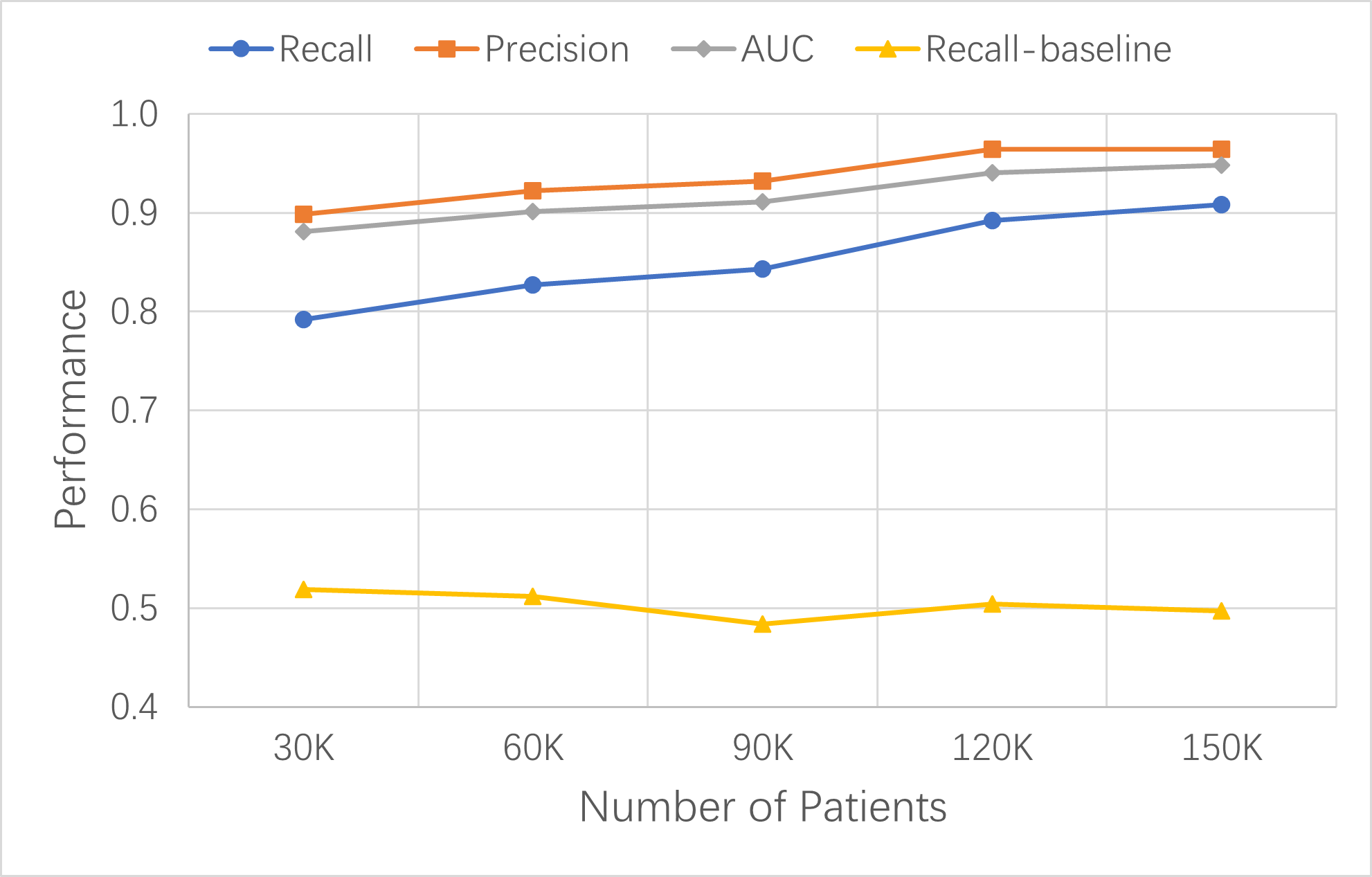
图示:脑梗风险预测 XGBoost 基础模型随着数据量增加而不断改进。 模型性能用召回率、精确度和 AUC 来衡量。含有 10 个变量的基础模型的召回率是基线。
ML-LHS 模拟研究结论
这项模拟研究创建了第一个合成 ML-LHS 单元,并示范了它能够用现有电子病历数据构建肺癌和脑梗等目标疾病的风险预测 XGBoost 基础模型。凭借它固有的数据驱动的机器学习方法,ML-LHS 可以不断从新的患者数据中学习和提高 ML 模型的性能。
合成 ML-LHS 流程可用于帮助使用真实患者数据构建疾病风险预测 ML-LHS。此外,还可以通过超参数 (hyperparameter) 调整进一步优化真实数据 ML 模型。
注:LHS 模拟中的 ML 模型仅能用于研究,不能用于实际医疗服务。
ML-LHS 假设
基于 ML-LHS 模拟研究,我提出两个假设:
- ML-LHS 性能假设:通过 LHS 内在的数据驱动 ML 方法,ML-LHS 单元最终可以为多数疾病的风险预测模型达到高召回率和精确率 (>95%) 。
- ML-LHS 平等假设:虽然社区和农村诊所可能没有足够的数据自行构建 ML 模型,但可以加入由大型医院主导的临床研究网络 (CRN),CRN 运行的 ML-LHS 将诊所数据综合纳入学习周期,从而诊所得到赋能,可以平等地使用相同水平的 ML 和 AI 工具。
6. 机器学习赋能的 LHS 项目实例
ML-LHS 非常有希望将医疗服务和公共卫生服务系统转变为更有效和更高质量的系统。我想在这里着重探讨一个我特别关心的应用领域:健康公平性。
减轻全球医疗服务不公平的潜在解决方案
ML-LHS 平等假设提出,ML-LHS 具有减轻农村及弱势群体的医疗不公平问题的潜力。尽管农村诊所和城市社区卫生中心 (CHC) 没有足够数量的患者来独自构建可完成各种临床任务的高精度 ML 模型,但 ML-LHS 设计可以扩展到临床研究网络 LHS (CRN-LHS), 覆盖 CRN 内的小型诊所。借助 CRN,教学医院或三级医院负责使用包含农村诊所和城市 CHC 的患者数据构建 ML 模型。由此产生的 ML 模型和 AI 工具可在 LHS 内迅速传播,结果是诊所和 CHC 也能使用大医院用的 ML 和 AI 工具。我预计,CRN-LHS 设计提供了一个有前景的解决方案,不仅可减少医疗服务不平等问题,还可以避免小型诊所在医疗 AI 革命中越来越落后。
ML-LHS 挑战
ML-LHS 的概念很有前景,但也面临着巨大的挑战。由于 LHS 同时开展系统层面的研究和临床实践,它对初始 ML 模型的要求明显更高,大多数报道的基于 EHR 数据的 ML 模型可能无法满足这样的 LHS 要求。此外,由于患者数据出于隐私原因无法公开共享,能开放获取的 ML-LHS 研发所需的患者数据集极为不足,开发者缺乏数据的问题严重限制了在新兴 LHS 领域广泛开展机器学习研究的可能性。
自从 2012 年 第一届全美智能医学系统峰会 以来(我有幸受邀参加),几乎没有看到医院临床流程实施和运营 ML- LHS 的文献报告,我期望看到的报告应该展现几个关键的 LHS 特征,包括自动数据收集、连续机器学习、新知识和最佳实践的快速传播等。尽管一些研究已经报告了应用 LHS 概念在医院服务流程中改善质量的成功案例,但这些实例并未采用电子病历数据进行持续机器学习 (Bravata 2020, Horwitz 2019),因此它们不属于 ML-LHS 一类的。
临床正在运营的 ML-LHS 实例
非常可惜,仍未见严格意义的 ML-LHS 原创文献报道。
- 实例:加州大学圣地亚哥分校医疗系统 LHS
UCSD El-Kareh 等在 LHS 杂志描述了加州大学圣地亚哥分校医疗系统的 LHS 现状 (El-Kareh 2022),其要点是:
- 在加州大学圣地亚哥分校医疗系统,COVID-19 大流行凸显了将高可靠性方法应用于实施智能医学系统的独特优势,重点明确地利用这两个框架的元素来研发“高度可靠的智能医学系统” 。
- 在运用临床数据建模和实施预测算法方面具有专业知识的研究人员成为运营团队的重要合作伙伴。
- 从电子病历持续挖掘数据生成了真实世界的证据,为当地医疗服务提供信息并影响国家政策。
- 高度可靠的智能医学系统的重点之一是应用临床研究社区的创新能力,与运营实施团队的可靠性特点结合起来。
(期待更多成功 LHS 案例……)
构建 ML-LHS 的新策略
由于 LHS 面临的挑战和进展缓慢,国际 LHS 社区 (global LHS community) 需要找到新途径来促进 ML-LHS 的研究和实施。
上述 LHS 模拟研究就是一个新尝试,试图用合成数据帮助医院或其他医疗机构更容易开始 ML-LHS 的研究探索。参照肺癌风险预测 ML-LHS 模拟的流程,华西医院 LHS 团队和桂林医学院附属医院的临床团队对研究人员和学生进行培训,然后使用真实病历数据快速研发出几种疾病的风险预测 ML 模型。该团队正在创建临床研究网络,以实施可提高疾病早期筛查和诊断的 ML-LHS。
根据合成数据模拟对加速医院启动 ML-LHS 研究项目的初步影响,我在这里提出一个新的加速 LHS 研究的策略,即“合成+真实”策略。它将构建 ML-LHS 的艰巨任务分解为两个阶段:
- 第一阶段:使用合成患者数据模拟 ML-LHS 的 ML 核心及流程,包括数据流程、ML 算法和团队培训。如果本阶段进行顺利,临床团队将更有信心实现 ML-LHS。
- 第二阶段:将模拟流程应用于真实 EHR 病历数据,进行标准数据收集、模型构建和临床验证。然后将研究的循环学习流程嵌入临床服务流程中,再使用医院已有质量评价方法对运行的 LHS 进行严格监控和科学评价。
征集 ML-LHS 实例
促进 ML-LHS 领域的发展需要成功案例,证明 ML-LHS 确实能为患者和医院带来益处和价值。如果您正在开展 ML-LHS 项目,可以通过 Learning Health Community的 LHS 技术论坛计划与我们联系。我们正在联系全球 LHS 社区的专家,收集 LHS 项目实例,了解 LHS 研究和实施面临的挑战,并组织国际 LHS 技术论坛,让产业界和学术界的创新者汇聚在一起,开展对话或合作。LHS 技术论坛计划的网页展示了论坛信息、LHS 资源和发表论文,还有成功 ML-LHS 案例。本指南也将分享更多 ML-LHS 实例。
在以下章节中,我将提供更多有关医疗健康数据、合成患者数据、数据驱动的机器学习等 ML-LHS 所需关键技术的详细信息。
7. 医疗健康数据
NAM 有关临床数据的报告
NAM 2010 研讨会总结报告《临床数据作为医疗系统学习进步的要素 —— 创造和保护一项公共利益》回顾了电子病历在知识产生中的整合和使用。报告讨论了为了调查前沿数据挖掘技术所作的努力,这些技术旨在生成有关医疗健康服务和研究的证据。
项目示例:癌症生物医学信息网格 (caBIG):连接多各生物医学研究和临床试验的参与系统,为癌症研究社区提供共享数据。
NAM 有关系统学习的数据报告
NAM 2013 研讨会总结报告《支持健康和医疗系统持续学习的数据改进的重要性》探讨了数据质量问题以及为知识产生而提高数字健康数据采集和应用的核心战略。
健康数据收集和共享的增加正迅速将医疗系统带入“大数据”时代。数字健康数据在各种不同的环境中产生:
- 电子病历含有日常医疗服务数据 (EHR) 。
- 直接源于患者的数据 (PGHD) 。
- 雇主握有的员工医疗服务使用数据、基本健康状况和相关医疗费用数据。
- 公共卫生系统及其调查和监测活动常规收集的人群健康数据。
- 正在进行和已完成的临床试验数据。
尽管大量健康及健康相关数据的收集有望支持医疗系统大规模和多类型的学习,但仅是数据还不够,还必需共享、整合、分析以及持续管理和提升这些数据,才能实现向持续学习的智能医学系统转型。
- 创新方法:需要研发使用电子病历作为数据源并对大数据进行观察研究的方法。需要研发、验证和使用预测模型来告知健康数据的使用,包括个人的健康风险解读。
- 分布式途径:鉴于数据隐私和安全对收集和使用患者健康数据的重要性,需要进一步研发和试点与分布式网络方法使用相关的政策、分析方法和技术。
- 分布式数据网络实例:FDA 小前哨网络(Mini-Sentinel, FDA 支持试点的计划):含有超过 1 亿人的分布式数据集,支持对医疗产品的主动安全监测。
电子病历的数据内容
以 MIMIC-IV 医院数据 为例,信息包括:
- 患者和入院详细信息 (patients, admissions, transfers)
- 实验室数值 (labevents, d_labitems)
- 微生物学培养 (microbiologyevents)
- 医嘱 (poe, poe_detail)
- 药物管理 (emar, emar_detail)
- 药物处方 (prescriptions, pharmacy)
- 医院账单信息 (diagnoses_icd, d_icd_diagnoses, procedures_icd, d_icd_procedures, hcpcsevents, d_hcpcs, drgcodes)
- 服务相关信息 (services)
患者数据的隐私安全
电子病历的患者数据必须得到隐私和安全的保护。尽管这意味着放慢研发速度,但我们使用患者数据必须遵守当地法律并符合产业标准 (McGraw 2021) 。
开放共享健康数据
适当开放共享部分脱敏的患者健康数据也很必要,因而有少数医疗机构开放了少量数据,这类开放数据要求使用者申请,被授权后才可得到脱敏患者数据。
共享 EHR 数据:
MIMIC-IV 是一个数据库,包含美国马萨诸塞州波士顿的一个三级教学医疗中心收治的患者的真实住院数据。每位患者的综合信息有:实验室数据、用药情况、生命体征记录等。该数据库旨在支持广泛的医疗服务研究。
MIMIC-III(重症病房数据集 III)是一个免费的大型数据库,包含 2001-2012 年间“贝斯以色列女执事医疗中心”重症监护病房的四万多名患者的脱敏健康数据。该数据库包括个人数据、床旁生命体征数值(每小时 1 个数据点)、实验室数据、手术、药物、护理人员记录、影像报告和死亡率(院内及院外)等信息。
CPRD 是一项真实世界临床数据的研究服务,支持回顾性和前瞻性的公共卫生和临床研究。CPRD 从全英国的全科医师服务网络收集匿名患者数据,涵盖 6,000 万患者,其中包括 1,600 万当前登记在册的患者。
PhysioNet Resource 的任务是开展和促进生物医学研究和教育,其中包括免费提供大规模生理和临床数据,以及相关开源软件。
临床研究数据共享:
政府和其他健康数据来源:
- 美国政府开放的健康数据
- 美国卫生部医改办 (ONC) 开放的医疗 IT 数据
- 美国政府医保局 (CMS) 的开放数据
- 美国卫生研究院 (NIH) 全民研究计划
- 美国卫生研究院全美数据与健康中心 (CD2H)
- 美国卫生研究院全美新冠合作研究联盟 (N3C) 数据
- 美国卫生研究院全美癌症研究所 (NCI) 癌症数据库
- 哈佛大学开放共享数据空间
- 哈佛大学生物医学信息系的自然语言处理数据集
- Elsevier Mendeley 开放共享数据平台
8. 合成患者病历数据
由于真实患者数据受到保护,为医疗系统研究和开发提供合成患者数据变得至关重要。完全从公开数据合成的患者数据应该不存在任何隐私问题。例如,Synthea 合成患者数据是根据公共数据合成的,因此最近被广泛用于研发和测试新的医疗服务信息流程。
Synthea 合成患者数据
Synthea 是一个开源的产生合成患者数据的软件,通过模拟虚构患者的病史,它可产生高质量、合成的、逼真但不真实的患者数据,而不受成本、隐私和安全性的限制。它使需要患者数据但却不能合法或实际取得数据的研究得以进行 (Walonoski 2018) 。
Synthea 开源软件:
Synthea 软件源代码 在 GitHub 上的 Synthea 项目网页。按照软件说明,您可以自己运行 Synthea 软件合成患者数据。更多信息见 Synthea wiki 。
Synthea 系统设计:
Synthea 系统采用基于代理的方法产生合成患者病历记录。每个合成患者都是独立生成的,从出生到死亡的过程中经历各种模块化表达的疾病或健康状况。每个患者都使用系统的所有疾病模块。
Synthea 疾病模块基于 通用模块框架,该框架使用一组预定义的状态、转换和条件逻辑,创建代表常见疾病的进展和诊疗标准的状态机 (state machines) 。模块是根据公开可用的健康数据构建的,包括疾病发病率和患病率统计数据,以及临床服务指南。
Synthea系统覆盖的疾病:
Synthea 目前有 90 多个不同的疾病模块,每个模块都模拟一种疾病或健康状态。模块构建工具页面列出了当前支持的所有疾病模块。模块库只列出一些常用疾病模块。
表格:Synthea 覆盖的最常见疾病和健康状况
| 患者看全科医生 (PCP) 的前十位原因 | 致死的前十位疾病和健康状况 |
|---|---|
| 婴幼儿定期健康检查 | 缺血性心脏病 |
| 原发性高血压 | 肺癌 |
| 糖尿病 | 阿尔茨海默病 |
| 正常妊娠 | 慢性阻塞性肺病 |
| 呼吸道感染(咽炎、支气管炎、鼻窦炎) | 脑血管疾病 |
| 一般成人体检 | 交通事故受伤 |
| 类脂代谢障碍 | 自残 |
| 耳部感染(中耳炎) | 糖尿病 |
| 哮喘 | 结直肠癌 |
| 尿路感染 | 药物使用障碍(仅限于大麻类控制药物) |
Synthea软件的可扩展性
Synthea 的模块设计很巧妙,您可以添加新模块来涵盖您感兴趣但 Synthea 软件尚未包含的疾病或健康状况。详情见以下功能页面:
Synthea 患者病历格式
Synthea 患者病历格式有标准的 FHIR 格式或简单的 CSV 格式。为了更方便地查看不同专项记录中的数据元素,请参阅 病历CSV文档列表 和每个文档中的数据字段。
表格:Synthea 患者病历文件
| 病历文档 | 解释 |
|---|---|
| allergies.csv | 患者过敏数据 |
| careplans.csv | 患者健康计划数据,包括目标 |
| claims.csv | 患者医保账单数据 |
| claims_transactions.csv | 患者医保账单项目明细数据 |
| conditions.csv | 患者诊断或健康状况 |
| devices.csv | 患者携带的永久性和半永久性医疗器械 |
| encounters.csv | 患者就诊数据 |
| imaging_studies.csv | 患者影像元数据 |
| immunizations.csv | 患者免疫接种数据 |
| medications.csv | 患者用药数据 |
| observations.csv | 患者观察结果数据,包括生命体征和实验室报告 |
| organizations.csv | 医院等医疗机构 |
| patients.csv | 患者个人数据 |
| payer_transitions.csv | 付费明细数据(即健康保险付费) |
| payers.csv | 支付机构数据 |
| procedures.csv | 手术等医疗流程数据 |
| providers.csv | 提供医疗服务的临床医生 |
| supplies.csv | 医用品数据 |
Synthea 数据验证
请参阅 Synthea 患者数据的外部验证研究文献 (Chen 2019)。
开放 Synthea 合成患者数据
- MITRE
Synthea 软件开发者 Mitre Corp(非营利机构)开放一个 100 万 Synthea 合成患者病历数据集,可从其 网站下载。Synthea 数据也可从 FHIR API 获取。
- 开放 LHS 项目 (Open LHS)
开放 LHS 项目在 GitHub 上启动了一个 “开放合成患者数据项目”,开放了以上 ML-LHS 模拟研究所用的肺癌和脑梗合成患者数据。因为数据量大,全部开放的合成患者数据发布在哈佛大学数据空间 (Dataverse) 上的 “机器学习用合成患者数据空间”。开放 LHS 项目今后陆续会在哈佛数据空间分享更多的合成患者数据。任何人可下载数据,无需申请。
其他合成患者数据
- MDClone:
MDClone 平台从真实患者队列数据产生完全合成的患者数据集,而没有暴露患者隐私的危险,并且能够安全地共享数据。MDClone 合成数据是不可逆的、人工合成的数据,它复制了真实世界原始数据的统计学特征和相关性。合成数据利用了关注的离散和非离散变量,使用了统计方法产生全新的数据集,因而不包含可识别真实患者身份的信息。例如,NIH N3C 项目使用 MDClone 从新冠患者数据生成了合成数据集,用于更广泛的研究。
- 英国 CPRD 合成患者数据:
英国的临床实践研究数据链 (CPRD) 使用全科医疗服务的患者数据产生高保真合成数据集,在复制了真实全科患者数据中的复杂临床关系的同时保护了患者隐私。CPRD 合成数据 可以代替真实患者数据,用于复杂的统计分析以及机器学习和人工智能研究应用。通过将异常值分析与图形建模和重采样相结合,CPRD 的方法可以产生合成数据集。在推断机器学习分类器时,合成数据在特征分布、特征依赖性和敏感性分析的统计结果方面与原始真实数据不存在显著差异。 CPRD 合成数据集可用于训练目的或改进算法或机器学习流程 (Tucker 2020) 。
- NCI SEER 癌症合成数据:
基于来自 NCI 监测流行病学和最终结果 (SEER) 项目的公开癌症登记数据,Goncalves 等人生成并评估了合成癌症患者数据 (Goncalves 2020)。 他们比较了现有的产生合成电子病历的几种方法,每种方法的流程如下:给定一组隐私和真实的 EHR 样本,拟合模型,然后用模型生成新的合成 EHR 样本。结果发现,多项式乘积混合 (MPoM) 方法和分类潜在高斯过程 (CLGP) 方法可以提供具有以下两个特征的合成 EHR 样本:(1)合成数据与隐私真实数据的统计学特性相当,(2)模型的隐私信息泄露并不显著。
使用合成患者数据的机器学习
- 如以上章节所述,我们使用 Synthea 患者数据建立了机器学习模型,模拟了 ML-LHS 单元 (Chen 2022)。
- IBM 研究组使用 100 万 Synthea 患者构建了 2D 患者路径,并进行神经网络 CNN 和 RNN 机器学习。产生的模型能够预测十种常见疾病,达到 80-90% 的准确度 (Sbodio 2021)。本研究使用开源的患者路径提取器 (patient pathway extractor),将 Synthea 病历转换成可用于机器学习的数据。
- 利用三个分别应用了分类和回归树、参数化和贝叶斯网络方法的合成数据生成器,Rankin 等人从 19 个开放健康数据集产生了合成数据。他们分别使用了合成数据和真实数据训练通用机器学习模型,然后使用独立的真实数据集来衡量模型性能。结果表明,与使用真实数据训练的模型相比,使用合成数据训练的模型的准确性仅略有下降 (Rankin 2020)。
Synthea合成患者数据的局限
Synthea 患者数据属于符合现实但并不是真实的数据。事实证明,Synthea 数据在开发和测试 ML 方法或流程方面很有用,但 Synthea 和真实患者数据之间的差异决定了 ML 模型的适用范围。Synthea 数据存在多种局限性,包括:疾病种类有限,一些数据偏向于特定患者人群,以及一些健康因素缺失,比如症状。由于这些差异,任何从合成数据构建的 ML 模型都不能用于实际临床服务。
9. LHS作为医疗人工智能框架
医疗服务人工智能
【资料来源:NAM 2019 特别人工智能报告】
NAM 2019 特别报告《医疗服务人工智能:希望、炒作、前途和危险》列出了当前和短期内的人工智能解决方案;强调 AI 在研发、应用和维护方面的挑战、局限和最佳实践;概述了为医疗应用设计的人工智能工具相关的法律和监管环境;优先考虑医疗人工智能对公平、包容和人权的需求;并提出向前推进的关键考虑因素 (NAM 2019,Matheny 2020) 。详情见网络研讨会 视频。
人工智能最早在 1950 年代提出并经历了两次“AI 寒冬”。 此次人工智能兴起,大约从 2010 年左右开始,得益于机器学习和数据科技的成功,以及计算存储和能力的显著增加。它推动了像谷歌、亚马逊和苹果等大型消费企业的发展。除了梯度提升、随机森林、支持向量机、人工神经网络等常见的机器学习技术外,基于各种神经网络的深度学习系统也将人工智能发展推向了新的高度。
人工智能有望在医疗健康领域取得变革性甚至颠覆性的进展。下表列出 NAM 报告中提到的机器学习在医疗健康领域的一些应用。
表格:机器学习的一些医疗健康服务应用
| 用户组 | 医疗健康服务应用 |
|---|---|
| 患者及家属 | 健康状况监测 |
| 患者及家属 | 疾病风险评估 |
| 患者及家属 | 疾病预防与管理 |
| 临床医生护理团队 | 早期检测、预测和诊断工具 |
| 临床医生护理团队 | 精准医疗和个性化医疗 |
| 公共卫生 | 发现高风险人群 |
| 公共卫生 | 人群健康 |
然而,在医疗服务中部署和使用 AI 的例子很少,并且鲜有证据表明部署 AI 工具后日常医疗服务结果得到了改善。例如,在机器学习风险预测模型研究邻域,有大量关于模型研发和验证的文献,但只有稀少文献数据描述这些模型在医疗临床服务中成功部署和日常应用,对比鲜明!
尽管如此,该报告描述了一个医疗服务系统和医院对临床 AI 应用进行评估、决策和采用的框架。它强调医疗人工智能应该在LHS智能医学系统的框架下部署和应用。 针对 NAM 2013《低成本的最佳医疗服务》报告中概述的十个推荐领域,它还描绘了该如何在 LHS 系统中考虑每个领域的人工智能问题。
【我的解读】
- 由于 LHS 将研究嵌入到医疗服务中,我们必须把 ML 模型的部署环节设计为医疗系统的有机组成部分。我认为这一要求和通常的ML和AI研究有本质区别,但是和 LHS 的要求是一致的。因此,部署越多 LHS,ML 和 AI 在医疗服务环境中部署和应用也将增加越多。
数据驱动的机器学习
现有的 ML/AI 研究通常缺乏以数据为中心的焦点。然而,近来人们认识到,以数据为中心的 ML/AI 与以模型为中心的 ML/AI 同样重要。
在以模型为中心的 ML 开发中,数据集通常是固定的,重点在于迭代模型架构或优化训练,以提高模型性能。
与此相反,以数据为中心的 ML 专注于系统方法,以评估、整合、清理和注释用于训练和测试 AI 模型的数据,这个流程有可能采用“交钥匙”模型构建器。
斯坦福大学研究人员在《自然机器智能》 (Nature Machine Intelligence) 杂志发表的最新论文讨论了为数据驱动的 AI 建立数据流的最新进展、最佳实践和相关资源 (Liang 2022)。这篇论文源自斯坦福 HAI中心举办的数据驱动 AI 研讨会(详见 报告回放录像)。
在《麻省理工学院管理》杂志 2022 年的采访中,吴恩达博士描述了为什么现在已经是时候侧重 数据驱动AI 的研究和应用了。如需了解他清晰的问题陈述和建议的解决方案,可观看吴博士关于以数据为中心 AI 的线上报告。您还可以在 https://datacentricai.org/ 加入由吴博士推动的数据驱动 AI 运动。
数据驱动和部署导向的 ML-LHS
我认为 LHS 本质上是一种以数据为中心的 (data-centric) ML 方法,这是由 LHS 的学习循环特征决定的。同时,LHS 还是以部署为导向的 (deployment-oriented) AI 策略。为解决医学知识的系统学习和传播问题,NAM 专家组在重新设计未来 LHS 智能医疗系统时已确认数据驱动和部署导向这两个必要特征,并提出 LHS 框架,把临床研究嵌入临床服务流程中,有机地结合数据驱动和部署导向。可见,这些年 LHS 的有关 ML 和 AI 策略的超前设计一直被忽略了,希望今后 LHS 社区能够把 LHS 的潜能发挥出来。
LHS = 医疗 AI 框架?
在 LHS 框架下,数据驱动与模型渠道并不互相排斥,而是互相补充。我在《自然科学报告》发表的模拟 ML-LHS 文章中提出,有必要在未来开展研究,探索结合以数据为中心和以算法为中心的两种方法的最佳策略。作为一般性建议,临床团队应当考虑首先使用ML基础模型开展数据驱动的学习循环,部署和运行起 ML-LHS,然后通过调整超参数或修改底层算法来进一步优化 ML 模型性能。
基于这个推理,我提出 ML-LHS 第 3 个新假设:
- ML-LHS AI 假设:因为 LHS 具有数据驱动和部署导向的特征,大部分基于电子病历数据的 AI 将以 LHS 形式更有效地实现和传播。
电子病历范围的机器学习
电子病历范围的机器学习 (EMR-wide ML) 指的是使用 EMR 中所有可得的健康因素和数据进行机器学习,这与仅限于使用少数预先选择的健康因素的传统建模不同。由于大量电子病历数据呈非结构化形式,因此全电子病历范围的机器学习通常使用自然语言处理 (NLP) 技术从文本中提取数据并进行标准化。
根据目标任务的不同,可以采用两大类机器学习算法来构建预测模型:
-
常见传统机器学习算法:梯度提升(例如 XGBoost)、随机森林 (RF)、支持向量机 (SVM)、等等。在传统的病历数据机器学习中,患者简单地由模型的属性或特征向量表示。这种方法依赖于专家定义恰当特征和设计模型结构的能力。
-
深度神经网络算法(或 深度学习):人工神经网络 (ANN)、卷积神经网络 (CNN)、递归神经网络 (RNN)、长短期记忆 (LSTM)、生成对抗网络 (GAN)、门控循环单元 (GRU)、前馈网络 (FFN),等等。深度学习模型可以从原始数据或最低限度处理的数据中学习有用的患者表达,而很少需要专家指导。这是通过一个序列层发生的,每一层都使用大量简单的线性和非线性变换,将其相应的输入映射到一个表达上面。跨层表达的发展会产生一个最终表达,其中数据点形成可区分的模式 (Li 2020, Solares 2020)。
以下文献报道的研究是 EMR 范围 ML 代表性实例:
-
斯坦福医学院研究小组使用美国一个州级健康信息交换站 (HIE) 的大量患者病历数据构建了一个 XGBoost 模型,用于预测一年肺癌发病风险,曲线下面积 (AUC) 为 0.881 (Wang 2019)。
-
美国西奈山医疗系统的研究人员开发了一种新颖的无监督深度特征学习方法,从 EHR 中的 700,000 名患者的数据推演出通用的患者表达,用以促进临床预测建模。该研究利用涵盖了 78 种疾病的76,214 名测试患者进行测试评估。结果明显优于使用基于原始病历数据和替代特征学习策略的患者表达所取得的结果 (Miotto 2016)。
-
使用大约 160 万患者病历和 57,000 个临床概念,西奈山医疗系统的研究人员创建了一个基于深度学习的无监督框架,可处理异构 EHR 数据,有效地把大量患者分组 (Landi 2020)。
-
谷歌健康的研究人员提出了用整个原始病历来表达患者的方法,并证明了使用这种患者表达的深度学习方法有能力准确预测来自多中心的多种医疗事件,而无需对各医疗中心进行数据协调。这些模型的性能在所有情况下都优于传统用于临床的预测模型 (Rajkomar 2018)。
-
牛津大学的研究人员基于 Transformer 架构和英国 CPRD 的 800 万患者而开发了一种称为 BEHRT(即 EHR 的 BERT)的模型,用于预测患者未来就诊时最有可能的疾病。与既往文献中最好的深度 EHR 模型相比,BEHRT 在预测超过 300 多种疾病方面的性能都优于前者达 8% 以上(绝对增加值) (Li 2020)。
-
一项详尽的对标评价研究中,使用开放的重症监护 III (MIMIC-III) 数据集,比较多项临床预测任务,深度学习模型的效果始终优于所有其他方法 (Purushotham 2018)。
-
目前缺乏在临床服务中对 ML 模型的前瞻性评估。《自然数字医疗》杂志 2022 年发表了一项模型构建以及临床验证和监测的示例。其流程首先确定一个可以从风险预测中获益的临床决策点,然后使用 EHR 数据回顾性地构建了一个预测居家癌症患者 60 天内到急诊室 (ED) 就诊的模型。模型在一项随机前瞻性研究中得到验证后,被嵌入临床流程,并日常监测模型性能 (Coombs 2022)。
10. LHS相关资源
更多 LHS 项目实例
-
FDA 哨兵系统:FDA 哨兵系统是智能医学系统的一个正在日常运营的实例,该系统正在扩展并有潜力创建一个全球智能医学系统,可以支持医疗产品安全性评估和其他研究 (Brown 2022) 。
-
凯撒医疗系统研究网络 (HCSRN):医疗系统研究网络(前身为 HMORN)汇集了许多来自全美最佳且最具创新性的医疗系统的研究中心。其使命是通过连接各成员 LHS 的资源和能力进行研究来改善个人健康和人群健康。
-
PCORnet PaTH 临床研究网络:作为 PCORnet 成员,PaTH 临床研究网络研究人员与临床医生、患者和其他利益相关者合作,提出有意义的研究问题,这些问题可以整合到医疗服务中以获取真实世界的健康数据。 PaTH 网络包括许多医院,例如盖辛格 (Geisinger)、约翰·霍普金斯 (Johns Hopkins)、宾州州立 (PennState)、俄亥俄州立 (Ohio State)、天普 (Temple)、匹兹堡 (Pittsburg)、匹兹堡大学医学中心 (UPMC)、密歇根 (Michigan) 等。
-
PEDsnet 儿童健康研究网络:PEDSnet 儿童健康研究网络开展改善儿童健康和生活的研究。它是一个由医院和医疗机构、研究人员和临床医生以及患者和家庭组成的大型全国性社区。社区共同努力以发现可以减少儿童痛苦并支持他们健康发展的最重要的研究问题。
-
ImproveCareNow 炎症性肠病合作社区:ImproveCareNow 是为改善青少年儿童克罗恩病和溃疡性结肠炎(也叫炎症性肠病)而运营的患者、家长、医生及研究人员共同参与的合作社区。
-
美国临床肿瘤学会 CancerLinQ:CancerLinQ 是美国临床肿瘤学会 (ASCO) 的健康技术子公司(非营利),其目标是为所有癌症患者提高医疗质量、改善健康结果,并推进循证医学研究。 CancerLinQ 建立了一个跨平台、跨学科和跨技能组合的学习社区,以促成改善可惠及各地患者的医疗服务。
-
斯坦福大学协作健康结果信息登记 (CHOIR) 网络:支持疼痛管理的斯坦福 CHOIR 网络是最早的开源、开放标准和高度灵活的平台,用于智能医疗系统优化医疗服务,并推进真实世界研究的发现和创新。
-
斯坦福大学医院新冠指南项目:在斯坦福大学医院新冠医疗服务LHS流程中,临床部门的临床问题得到快速回答,并及时影响服务新冠患者的医院指南的制定 (Dash 2022)。
-
退伍军人医院短暂性脑缺血发作 LHS 项目:退伍军人医院 PREVENT 临床试验项目旨在尝试智能医疗系统的服务模式,评估多组分 QI 干预,以提高短暂性脑缺血发作 (TIA) 的医疗质量 (Bravata 2020)。
-
纽约大学 Langone 医院 LHS 项目:在纽约大学医院的医疗创新和实施科学中心 (NYU CHIDS),随机 QI 项目是与一线医护人员合作,确保 QI 干预无缝实施,而不会增加额外负担。项目证实了 LHS 在系统层面的干预可有效提高医疗质量。见研讨会视频 (Horwitz 2019)。
研究和开发
医疗系统
社区
教育
政策
- US NAM: 智能医学系统系列报告.
- US HHS AHRQ: 智能医学系统转型支持
参考资料
-
Abraham, E., C. Blanco, C. Castillo Lee, J. B. et al. 2016. Generating Knowledge from Best Care: Advancing the Continuously Learning Health System. NAM Perspectives. Discussion Paper, National Academy of Medicine, Washington, DC. https://doi.org/10.31478/201609b
-
Balas, E, and S Boren. 2000. Managing clinical knowledge for healthcare improvements. In Yearbook of Medical Informatics, edited by V Schatauer. Stuttgart, Germany: Schattauer Publishing.
-
Bravata DM, Myers LJ, Perkins AJ, et al. Assessment of the Protocol-Guided Rapid Evaluation of Veterans Experiencing New Transient Neurological Symptoms (PREVENT) Program for Improving Quality of Care for Transient Ischemic Attack: A Nonrandomized Cluster Trial. JAMA Netw Open. 3(9), e2015920 (2020). doi:10.1001/jamanetworkopen.2020.15920
-
Brown JS, et al. The US Food and Drug Administration Sentinel System: a national resource for a learning health system, JAMIA, 2022; ocac153, https://doi.org/10.1093/jamia/ocac153.
-
Chen, A., Chen, D.O. Simulation of a machine learning enabled learning health system for risk prediction using synthetic patient data. Sci Rep 12, 17917 (2022). https://doi.org/10.1038/s41598-022-23011-4
-
Chen J, Chun D, Patel M, Chiang E, James J. The validity of synthetic clinical data: a validation study of a leading synthetic data generator (Synthea) using clinical quality measures. BMC Med Inform Decis Mak. 2019;19(1):44. doi: 10.1186/s12911-019-0793-0.
-
Coombs, L., Orlando, A., Wang, X. et al. A machine learning framework supporting prospective clinical decisions applied to risk prediction in oncology. npj Digit. Med. 5, 117 (2022). https://doi.org/10.1038/s41746-022-00660-3
-
Dash D, Gokhale A, Patel BS, et al. Building a Learning Health System: Creating an Analytical Workflow for Evidence Generation to Inform Institutional Clinical Care Guidelines. Appl Clin Inform. 2022;13(1):315-321. doi: 10.1055/s-0042-1743241.
-
El-Kareh R, Brenner DA, Longhurst CA. Developing a highly-reliable learning health system. Learning Health Systems. 2022;e10351. https://doi.org/10.1002/lrh2.10351
-
Friedman CP, Wong AK, Blumenthal D. Achieving a nationwide learning health system. Sci Transl Med. 2010 Nov 10;2(57):57cm29. doi: 10.1126/scitranslmed.3001456. PMID: 21068440.
-
Goncalves, A., Ray, P., Soper, B. et al. Generation and evaluation of synthetic patient data. BMC Med Res Methodol 20, 108 (2020). https://doi.org/10.1186/s12874-020-00977-1.
-
Horwitz LI, Kuznetsova M, Jones SA. Creating a Learning Health System through Rapid-Cycle, Randomized Testing. N Engl J Med. 2019 Sep 19;381(12):1175-1179. doi: 10.1056/NEJMsb1900856. https://www.nejm.org/doi/full/10.1056/NEJMsb1900856
-
Institute of Medicine. 2001. Crossing the Quality Chasm: A New Health System for the 21st Century. Washington, DC: The National Academies Press. https://doi.org/10.17226/10027.
-
Institute of Medicine. 2007. The Learning Healthcare System: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/11903.
-
Institute of Medicine. 2010. Clinical Data as the Basic Staple of Health Learning: Creating and Protecting a Public Good: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/12212.
-
Institute of Medicine. 2011. Digital Infrastructure for the Learning Health System: The Foundation for Continuous Improvement in Health and Health Care: Workshop Series Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/12912.
-
Institute of Medicine and National Academy of Engineering. 2011. Engineering a Learning Healthcare System: A Look at the Future: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/12213.
-
Institute of Medicine. 2013. Best Care at Lower Cost: The Path to Continuously Learning Health Care in America. Washington, DC: The National Academies Press. https://doi.org/10.17226/13444.
-
Institute of Medicine. 2013. Observational Studies in a Learning Health System: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/18438.
-
Institute of Medicine. 2013. Large Simple Trials and Knowledge Generation in a Learning Health System: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/18400.
-
Institute of Medicine. 2013. Digital Data Improvement Priorities for Continuous Learning in Health and Health Care: Workshop Summary. Washington, DC: The National Academies Press. https://doi.org/10.17226/13424.
-
Landi, I., Glicksberg, B.S., Lee, HC. et al. Deep representation learning of electronic health records to unlock patient stratification at scale. npj Digit. Med. 3, 96 (2020). https://doi.org/10.1038/s41746-020-0301-z
-
Li, Y., Rao, S., Solares, J.R.A. et al. BEHRT: Transformer for Electronic Health Records. Sci Rep 10, 7155 (2020). https://doi.org/10.1038/s41598-020-62922-y.
-
Liang, W., Tadesse, G.A., Ho, D. et al. Advances, challenges and opportunities in creating data for trustworthy AI. Nat Mach Intell (2022). https://doi.org/10.1038/s42256-022-00516-1
-
Masoudi, F. A., E. P. Havranek, P. Wolfe, C. P. Gross, S. S. Rathore, J. F. Steiner, D. L. Ordin, and H. M. Krumholz. 2003. Most hospitalized older persons do not meet the enrolment criteria for clinical trials in heart failure. American Heart Journal. 146(2):250-257. https://doi.org/10.1016/S0002-8703(03)00189-3.
-
Matheny ME, Whicher D, Thadaney Israni S. Artificial Intelligence in Health Care: A Report From the National Academy of Medicine. JAMA. 2020;323(6):509–510. doi:10.1001/jama.2019.21579. https://jamanetwork.com/journals/jama/article-abstract/2757958
-
McGraw, D., Mandl, K.D. Privacy protections to encourage use of health-relevant digital data in a learning health system. npj Digit. Med. 4, 2 (2021). https://doi.org/10.1038/s41746-020-00362-8
-
Miotto, R., Li, L., Kidd, B. et al. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci Rep 6, 26094 (2016). https://doi.org/10.1038/srep26094.
-
NAM, 2019. “Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. A Special Publication from the National Academy of Medicine.” https://nam.edu/artificial-intelligence-special-publication/
-
Purushotham S, et al. Benchmarking deep learning models on large healthcare datasets. J. Biomed. Inf. 2018; 83:112-134. Doi: 10.1016/j.jbi.2018.04.007.
-
Rajkomar, A., Oren, E., Chen, K. et al. Scalable and accurate deep learning with electronic health records. npj Digital Med 1, 18 (2018). https://doi.org/10.1038/s41746-018-0029-1
-
Rankin D, et al. Reliability of Supervised Machine Learning Using Synthetic Data in Health Care: Model to Preserve Privacy for Data Sharing. JMIR Med Inform. 2020 Jul 20;8(7):e18910. doi: 10.2196/18910. https://pubmed.ncbi.nlm.nih.gov/32501278/.
-
Sbodio ML, Mulligan N, Speichert S, Lopez V, Bettencourt-Silva J. Encoding Health Records into Pathway Representations for Deep Learning. Stud Health Technol Inform. 2021;287:8-12. doi: 10.3233/SHTI210800. https://pubmed.ncbi.nlm.nih.gov/34795069/.
-
Seid M, Hartley DM, Margolis PA. A science of collaborative learning health systems. Learn Health Sys. 2021; 5(3):e10278. https://doi.org/10.1002/lrh2.10278
-
Solares JRA, et al. Deep learning for electronic health records: A comparative review of multiple deep neural architectures. J Biomed Inform. 2020;101:103337. doi: 10.1016/j.jbi.2019.103337. PMID: 31916973.
-
Tucker, A., Wang, Z., Rotalinti, Y. et al. Generating high-fidelity synthetic patient data for assessing machine learning healthcare software. npj Digit. Med. 3, 147 (2020). https://doi.org/10.1038/s41746-020-00353-9.
-
Walonoski J, et al. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record, JAMA, 2018, https://doi.org/10.1093/jamia/ocx079.
-
Wang X, et al. Prediction of the 1-Year Risk of Incident Lung Cancer: Prospective Study Using Electronic Health Records from the State of Maine. J Med Internet Res 2019;21(5):e13260. doi: 10.2196/13260
鸣谢
感谢韩若冰女士帮助翻译本指南。感谢 Joshua C. Rubin, JD, MBA, MPH, MPP 审阅和编辑本指南。特别感谢美国医学科学院发表 LHS 系列报告,如果没有他们开创性的研究,就不可能有 LHS 的方向。感谢所有引用的参考资料。
©2022-2023 陈安均,版权所有。